Table of Contents [expand]
Last updated December 03, 2024
Heroku provides the runtime and manages the execution and scale of your application. However, in order for an application to be properly managed, it must adhere to a few runtime principles.
These runtime principles are one of several categories of best practices when developing for Heroku. Review all the principles of architecting applications to gain a complete understanding of properly developing apps on Heroku.
Process Model
Applications are not be executed as monolithic entities. Instead, run them as one or more lightweight processes. During development this can be a single process launched via the command line. In production, a sophisticated app may use many process types, instantiated into zero or more running processes.
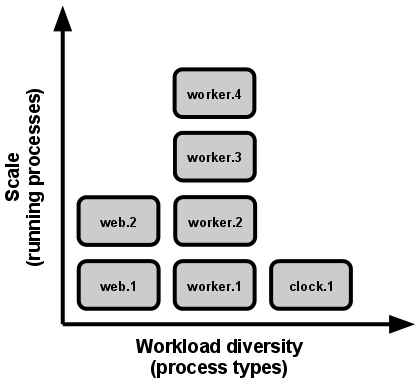
Processes on Heroku take strong cues from the unix process model for running service daemons. Using this model, you can architect your app to handle diverse workloads by assigning each type of work to a process type. Common process types include web which handle incoming HTTP requests and worker which run background jobs. These various process types are specified in a Procfile, which defines the execution model for your app.
Heroku dynos are virtualized containers responsible for running the processes defined by your application. A single dyno runs a single instance of a process type (which itself can then spawn and manage several sub-processes). Superficially, it is convenient to think of each of your app’s dynos as managing a single root process, a 1-1 relationship.
Statelessness
Processes are stateless and share-nothing. Any data that needs to persist must be stored in a stateful backing service, typically a database.
Never assume that anything cached in memory or on disk is available on a future request or job for apps. With many processes running in a distributed environment, chances are high that a future request will be served by a different process with a different physical location which won’t have access to the original memory or filespace. Even when running only one process, a restart (triggered by code deploy, config change, or the execution environment relocating the process to a different physical location) will usually wipe out all local (e.g., memory and filesystem) state.
This process model truly shines when it comes time to scale out. Its share-nothing, horizontally partitionable nature means that adding more concurrency is a simple and reliable operation.
Foreground Execution
Processes should never daemonize or write PID files. Instead, rely on the dyno manager, or a tool like heroku local in development, to manage output streams, respond to crashed processes, and handle user-initiated restarts and shutdowns.
Web Servers
Outside of Heroku, web apps are sometimes executed inside a web server container. For example, PHP apps might run as a module inside Apache HTTPD, or Java apps might run inside Tomcat.
On Heroku, apps are completely self-contained and do not rely on runtime injection of a webserver into the execution environment to create a web-facing service. Each web process simply binds to a port, and listens for requests coming in on that port. The port to bind to is assigned by Heroku as the PORT environment variable.
This is typically implemented by using dependency declaration to add a webserver library to the app, such as Tornado for Python, Unicorn for Ruby, or Jetty for Java and other JVM-based languages. This happens entirely in user space, that is, within the app’s code. The contract with Heroku is for the process to bind to a port to serve requests. Heroku’s routers are then responsible for directing HTTP requests to the process on the right port.
Disposability
Consider app processes to be disposable – they can be started or stopped at a moment’s notice. This facilitates fast elastic scaling, rapid deployment of code or config changes, and robustness of production deploys.
Processes strive to minimize startup time, being ready to receive requests within a few seconds. Conversely, processes shut down gracefully when they receive a SIGTERM signal. For a web process, graceful shutdown is achieved by ceasing to listen on the service port (thereby refusing any new requests), allowing any current requests to finish, and then exiting.
Implicit in this model is that HTTP requests are short (no more than a few seconds), or in the case of long polling, the client seamlessly attempt to reconnect when the connection is lost.
Build, Release, Run
A codebase is transformed into a running application through three stages: build, release and run. Using strict separation between these stages ensures a consistent and predictable release pipeline.
The build stage converts a code repo into an executable bundle by first fetching and vendoring dependencies and subsequently compiling binaries and assets. The release stage then takes the build and combines it with the deploy’s current config. The resulting release contains both the build and the config and is ready for immediate execution.
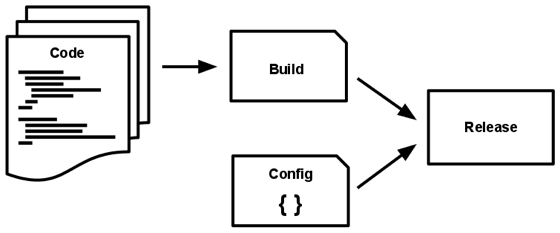
The run stage (also known as “runtime”) then runs the executable bundle in the execution environment. By keeping the run stage to as few moving parts as possible, problems that prevent an app from running are minimized.
Heroku’s well-structured build process exposes opportunities for extensibility (in custom buildpacks), ensures the ability to quickly propagate configuration changes (with heroku config:set), and allows for powerful platform-managed features such as immediately rolling back an errant release. While not a principle that manifests itself in your app’s architecture, the strict separation between the three deploy stages is an important concept in understanding the transformation of your app’s codebase into a running app.