Table of Contents [expand]
この記事の英語版に更新があります。ご覧の翻訳には含まれていない変更点があるかもしれません。
最終更新日 2025年09月02日(火)
Apache Kafka Connector は、Apache Kafka やその他のシステムまたはデータストア間でデータを移動または変更するために設計されたパッケージアプリケーションです。これらは、Apache Kafka Connect フレームワークを使用して作成されます。Apache Kafka Connect フレームワークにより、データベースへのデータの同期などの一般的なデータ転送タスクを作成してバンドルすることが容易になります。これは、開発者が自分のユースケースに固有の作業に焦点を絞ることができるように、そのタスクに固有ではない機能を処理することによって行われます。この記事は、Heroku で事前に作成されたコネクターを実行するための考慮事項に重点を置いています。カスタムコネクターを作成することを計画している場合は、「Connector Developer Guide」(コネクター開発者ガイド) に従うことができます。その場合、コネクターが Heroku でスムーズに動作するように、この記事の考慮事項を念頭に置いておいてください。
Premier または Signature Success Plan の Heroku Enterprise の顧客は、Customer Solutions Architecture (CSA) チームに、このトピックに関する詳細なガイダンスを要求できます。ここでエキスパートコーチングセッションについて学習するか、または Salesforce の担当者にお問い合わせください。
コネクターの種類
コネクターには、次の 2 種類があります。
ソースコネクター - これらのコネクターは Apache Kafka へデータを送信するために使用されます。
シンクコネクター - これらのコネクターは Apache Kafka からデータを取得するために使用されます。
多くのコネクターは、設定に応じてソースまたはシンクのどちらかとして機能できます。次に示すのは、Postgres 内の変更を監視し、それを Apache Kafka の対応するトピックに追加するデータベースコネクターの例です。このコネクターはまた、反対の方向に動作して、Apache Kafka から Postgres 内のテーブルに変更を追加することもできます。
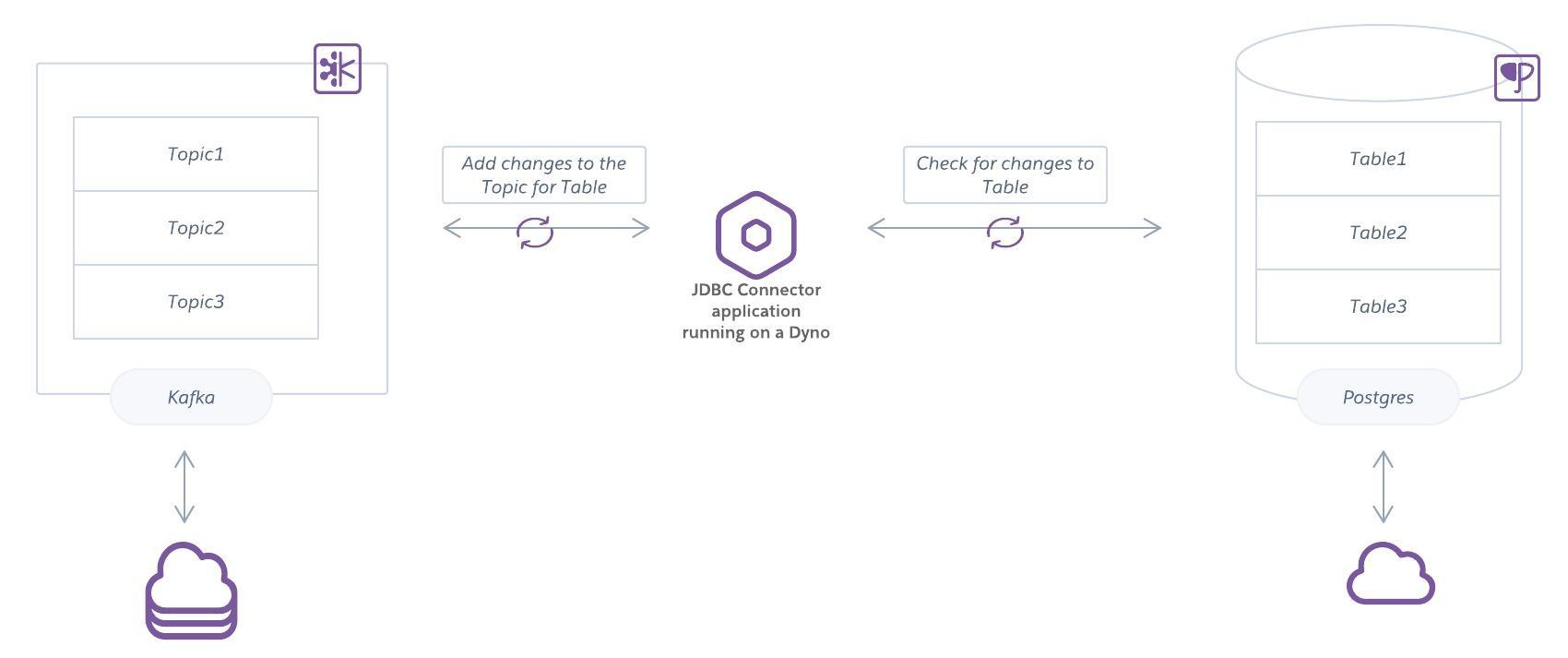
Apache Kafka のための事前に作成されたコネクター
一般的なタスクのためのコネクターは、GitHub や Apache Kafka エコシステムのページで見つけることができます。
既存のコネクターのライセンスと技術的要件の両方がアプリケーションに適していることを確認してください。コネクターによっては、ライセンスの制限があるか、または Kafka が自動的に管理されるクラウド環境ではなく、ユーザーが直接管理する環境を対象にしているものがあります。特に、Heroku でコネクターを実行するためのいくつかの考慮事項を見てみましょう。
Heroku でのコネクターの実行
Heroku では、コネクターは、Kafka Connect API を使用してデータを生成または消費することによって Apache Kafka クラスターにアクセスするアプリケーションです。
互換性
Heroku でコネクターを実行する前に、それを次の条件に対して評価してください。
長期間のローカル保存
Heroku dyno には一時的なファイルシステムがあり、ローカルデータが 24 時間を超えて存在することはありません。長期間のローカル保存を必要とするコネクターは互換性がありませんが、一部のコネクターはこの要件を変更するように設定できます。
自動的なトピック作成
一部のコネクターは状態を管理するためにトピックを自動的に作成しますが、Apache Kafka on Heroku は現在、自動的なトピック作成をサポートしていません。特定のトピックが必要なコネクターを使用するには、それを事前に作成し、コネクターで最初の書き込み時の作成を無効にします。自動的なトピックのハード要件があるコネクターは Heroku と互換性がありません。
オペレーターレベルのクラスターアクセス
Apache Kafka クラスターへのオペレーターレベルのアクセス (クラスター設定の変更など) が必要なコネクターは、Apache Kafka on Heroku と互換性がありません。Apache Kafka on Heroku は、Heroku が更新、稼働時間、メンテナンスに責任を負うマネージドサービスです。
他のシステムへのオペレーターレベルのアクセス
接続されているシステム (PostgreSQL など) へのオペレーターレベルのアクセスが必要なコネクターは、Apache Kafka on Heroku と互換性がありません。たとえば、Debezium PostgreSQL コネクターでは、PostgreSQL サーバーに出力プラグインをインストールする必要があります。これにより、マネージド Heroku PostgreSQL サービスで許可されているものを超えるアクセスが必要になります。
操作
Heroku でコネクターを操作する場合は、次のガイドラインに従ってください。
タスクのスケーリング
コネクターがサポートし、複数のインスタンス (分散ワーカー) を実行するように設定されている場合は、Heroku 上の他のすべてのアプリケーションと同様にスケーリングできます。
タスクの監視
タスクにどれだけ高い回復性が必要かということも考慮する必要があります。たとえば、このドキュメントに記載されているように、「タスクが失敗した場合、タスクの失敗は例外的なケースとみなされるため、再分散はトリガーされません。このため、失敗したタスクはフレームワークによって自動的には再起動されず、REST API 経由で再起動する必要があります。」つまり、タスクを監視していない場合は、想定どおりに処理されない可能性があります。New Relic や同様のサービスなど、Heroku 上の別のアプリケーションと同じようにコネクターアプリケーションを監視できます。
設定の管理
一部のコネクターは、設定をプロパティファイルに保存します。Heroku では、12 要素アーキテクチャに従います。これは、設定を環境設定として環境内に保存するように指定します。
プロパティファイルが必要なコネクターを使用するには、コネクタープロセスを起動する前に環境設定に基づいてファイルを書き込む初期化スクリプトを作成できます。このリポジトリの例では、dyno の起動時にその Procfile によって起動される起動分散スクリプトを使用して設定ファイルを書き込みます。
システムパッケージのインストール
dyno は、Heroku によってキュレートおよび維持されているオペレーティングシステムイメージであるスタック上で動作します。各スタックには、インストールされたシステムパッケージのセットが含まれています。
Kafka Connector に追加のパッケージが必要な場合は、Apt Buildpack や Aptfile を使用してインストールできます。このプロセスについての詳細は、「サードパーティ buildpack の使用」を参照してください。なお、apt は Cloud Native Buildpack を使用するアプリに含まれているため、Apt Buildpack を別途追加する必要はありません。
必要なパッケージを Apt Buildpack でインストールできない場合は、代わりに Docker デプロイを使用できる可能性があります。