Table of Contents [expand]
Last updated January 13, 2026
One of the big selling points of Postgres is how it handles concurrency. The promise is simple: reads never block writes and vice versa. Postgres achieves this via a mechanism called Multi Version Concurrency Control. This technique isn’t unique to Postgres: there are several databases that implement some form of MVCC including Oracle, Berkeley DB, CouchDB and many more. Understanding how MVCC is implemented in Postgres is important when designing highly concurrent apps on PostgreSQL. It’s actually an elegant and simple solution to a hard problem.
How MVCC works
Every transaction in Postgres gets a transaction ID called XID. This includes single one statement transactions such as an insert, update, or delete, as well as explicitly wrapping a group of statements together via BEGIN - COMMIT. When a transaction starts, Postgres increments an XID and assigns it to the current transaction. Postgres also stores transaction information on every row in the system, which is used to determine whether a row is visible to the transaction or not.
For example, when you insert a row, Postgres stores the XID in the row and calls it xmin. Every row that has been committed and has an xmin that is less than the current transaction’s XID is visible to the transaction. This means that you can start a transaction and insert a row, and until that transaction COMMITs that row isn’t visible to other transactions. After it commits and other transactions get created, they’re able to view the new row because they satisfy the xmin < XID condition – and the transaction that created the row has completed.
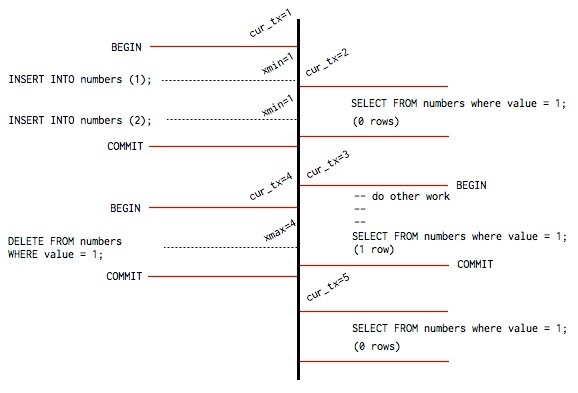
A similar mechanism occurs for DELETEs and UPDATEs, only in these cases Postgres stores an xmax value on each row in order to determine visibility. This diagram shows two concurrent transactions inserting and reading rows, and how MVCC comes into play in terms of transaction isolation.
For the following charts, assume the following DDL:
CREATE TABLE numbers (value int);
While the xmin and xmax values are hidden from daily operations, you can just ask for them and Postgres gives them to you:
SELECT *, xmin, xmax FROM numbers;
You can also get the XID for the current transaction easily:
SELECT txid_current();
Neat!
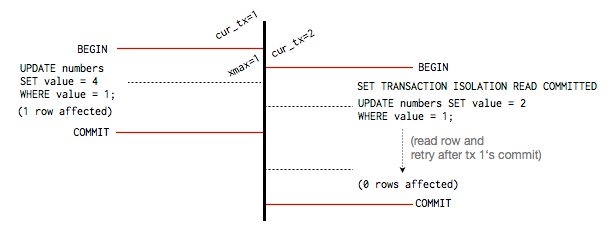
I know what you’re thinking though: what about a two transactions updating the same row at the same time? This is where transaction isolation levels come in. Postgres basically supports two models that allow you to control how this situation is handled. The default, READ COMMITTED, reads the row after the initial transaction has completed and then executes the statement. It basically starts over if the row changed while it was waiting. For instance, if you issue an UPDATE with a WHERE clause, the WHERE clause will rerun after the initial transaction commits, and the UPDATE takes place if the WHERE clause is still satisfied. Here’s an example of two transactions modifying a row where the initial UPDATE causes the WHERE clause of the second transaction to return no rows. Therefore the second transaction doesn’t update any rows at all:
If you need finer control over this behavior, you can set the transaction isolation level to SERIALIZABLE. With this strategy the above scenario fails because it says “If the row I’m modifying has been modified by another transaction, don’t even try,” and Postgres responds with the error message ERROR: could not serialize access due to concurrent update. It’s up to your app to handle that error and try again, or to give up if that’s what makes sense.

Disadvantages of MVCC
Now that you know how MVCC and transaction isolation actually works, you’ve added another tool for solving the kinds of problems where a SERIALIZABLE isolation level comes in handy. While the advantages of MVCC are clear it also has some disadvantages.
Because different transactions have visibility to a different set of rows, Postgres must maintain potentially obsolete records. This is why an UPDATE actually creates a new row and why DELETE doesn’t really remove the row: it merely marks it as deleted and sets the XID values appropriately. As transactions complete, there will be rows in the database that can’t possibly be visible to any future transactions. These are called dead rows. Another problem that comes from MVCC is that transaction IDs can only ever grow so much – they’re 32 bits and can “only” support around 4 billion transactions. When the XID reaches its max, it wraps around and starts back at zero. Suddenly all rows appear to be in future transactions, and no new transactions would have visibility into those rows.
Both dead rows and the transaction XID wraparound problem are solved with VACUUM. This is routine maintenance, but thankfully Postgres comes with an auto_vacuum daemon that runs at a configurable frequency. It’s important to keep an eye on this because different deployments have different needs when it comes to vacuum frequency. You can read more about what VACUUM actually does on the Postgres docs and how Heroku handles it.