この記事の英語版に更新があります。ご覧の翻訳には含まれていない変更点があるかもしれません。
最終更新日 2020年11月24日(火)
This article was contributed by Will Webberley
Will is a computer scientist and is enthused by nearly all aspects of the technology domain. He is specifically interested in mobile and social computing and is currently a researcher in this area at Cardiff University.
Web アプリケーションには多くの場合、ユーザーが画像、ムービー、アーカイブなどのファイルをアップロードできるようにする機能が必要になります。 Amazon S3 は、これらのファイルのための一般的で信頼性の高いストレージオプションです。
この記事では、S3 のオリジン間リソース共有 (CORS) サポートを利用して、Web アプリケーションを経由せずにファイルを S3 に直接アップロードする Python アプリケーションを作成する方法の例を示します。この記事とコンパニオンリポジトリでは Python 2.7 について考慮していますが、後で注記されている点を除き、Python 3.3 以上ともほぼ互換性があります。
S3 への直接アップロード
この記事で説明するコードの完全な例は、この GitHub リポジトリから入手して直接使用できます。
直接アップロードの主な利点は、アプリケーションの dyno への負荷が大幅に削減されることです。ファイルの受信と S3 への転送にサーバー側のプロセスを使用すると、dyno が不必要に拘束され、並列 Web リクエストへの dyno の応答効率が低下する可能性があります。
アプリケーションがクライアントのコンピュータと S3 の間の何らかの形式のファイル処理 (Exif 情報の解析や画像への透かしの適用など) に依存している場合は、追加の dyno を使用し、アップロードを Web サーバーに渡すことが必要になる可能性があります。
アプリケーションでは、クライアント側の JavaScript と Python を使用してリクエストに署名します。そのため、これは Flask、Bottle、Django などの Web フレームワーク用のアプリケーションを開発するための適切なガイドになります。アップロードは非同期で実行されるため、アップロードの完了後にアプリケーションのフローを処理する方法は開発者が決定できます (たとえば、アップロードが成功したら、完全にページを更新する代わりにページにリダイレクトできます)。
直接アップロードを実行するために必要な各種の手順を完了するためのガイドとして、また、より広範囲のユースケースにこのアプリケーションを関連付けるために、単純なアカウント編集シナリオの例を使用しています。このシナリオについての詳細は、後で説明します。
概要
S3 は、それぞれにグローバル固有名が付いており、個々のファイル (オブジェクトと呼ばれる) やディレクトリを保存できる一連のバケットで構成されています。
ファイルを S3 にアップロードするには、ユーザー名とパスワードの役割を果たすアクセスキー ID とシークレットアクセスキーが必要です。アップロードを成功させるには、ターゲットバケットに対する十分なアクセス権限がアクセスキーアカウントに必要です。
これについての詳細、バケットの作成、およびアクセスキー ID とシークレットアクセスキーの検索については、S3 関連の記事を参照してください。
この記事で説明されている方法には、クライアント側の JavaScript とサーバー側の Python の使用が含まれています。一般に、完成した画像アップロードプロセスは次の手順に従います。
- アップロードするファイルをユーザーが Web ブラウザで選択します。
- 次に、JavaScript によってHeroku 上の Web アプリケーションにリクエストが行われます。これにより、アップロードリクエストへの署名に使用される一時的な署名が生成されます。
- 一時的に署名されたリクエストが JSON 形式でブラウザに返されます。
- 次に、Python アプリケーションによって提供された署名済みリクエストを使用して、JavaScript から Amazon S3 に直接、ファイルがアップロードされます。
このガイドには、完全なシステムを構築するために、クライアント側およびサーバー側のコードを実装する方法についての情報が含まれています。ガイドに従って完成した、最低限の機能を持つシステムを使用して、ユーザーはファイルを S3 にアップロードできます。ただし通常は、システムのセキュリティを強化したり、特定の用途に合わせてカスタマイズしたりするために、さらに機能を追加する価値があります。これについては、ガイド内の別の箇所で説明します。
前提条件
- Heroku CLI がインストールされていること。
- 現在のプロジェクトのための Heroku アプリケーションが作成されていること。
- AWS S3 バケットが作成されていること。デモンストレーションの目的で、パブリックオブジェクトの作成を許可するバケットが作成されていることを前提にしています。本番環境では、署名済みの URL 経由でアクセスできるプライベートオブジェクトを使用することもできます。
バケットが作成されてから最初の数時間は、アップロードリクエストへの応答として S3 からリダイレクトが返される可能性があります。この動作に気付いた場合は、新しいバケットが完全に落ち着くまで少し待つと、この問題は解決されます。
初期設定
Heroku の設定
アップロードリクエストに署名するために、アプリケーションが AWS の資格情報にアクセスする必要がある場合、その資格情報は Heroku で環境設定として追加する必要があります。
デプロイの前にローカルでテストしている場合は、ローカルマシンの環境にも忘れずに資格情報を追加してください。
$ heroku config:set AWS_ACCESS_KEY_ID=xxx AWS_SECRET_ACCESS_KEY=yyy
Adding config vars and restarting app... done, v21
AWS_ACCESS_KEY_ID => xxx
AWS_SECRET_ACCESS_KEY => yyy
AWS のアクセス資格情報に加えて、ターゲットの S3 バケットの名前 (そのバケットの ARN ではない) を次のように設定します。
$ heroku config:set S3_BUCKET=zzz
Adding config vars and restarting app... done, v21
S3_BUCKET => zzz
セキュリティ上の理由から、設定ファイルではなく環境設定を使用することをお勧めします。パスワードやアクセスキーをアプリケーションのコードまたは設定ファイルに直接記述することはできるだけ避けてください。
S3 の設定
ここでは、ターゲットの S3 バケットの権限プロパティの一部を編集して、最終的なリクエストがバケットに書き込むための十分な権限を持つようにする必要があります。Web ブラウザで、AWS コンソールにサインインして [S3] セクションを選択します。適切なバケットを選択し、Permissions (アクセス許可) タブをクリックします。このページにはいくつかのオプションが提供されています (パブリックアクセスのブロック、アクセス制御リスト、バケットポリシー、CORS 設定など)。
最初に、"Block all public access" (すべてのパブリックアクセスをブロックする) をオフにします。特に “Block public access to buckets and objects granted through new access control lists” (新しいアクセス制御リスト経由で許可されたバケットおよびオブジェクトへのパブリックアクセスをブロックする) および “Block public access to buckets and objects granted through any access control lists” (任意のアクセス制御リスト経由で許可されたバケットおよびオブジェクトへのパブリックアクセスをブロックする) を、このプロジェクトのためにオフにします。バケットをこの方法で設定すると、署名済みの URL がなくてもそのコンテンツを読み取ることができますが、これは本番環境で実行中のサービスには適さないことがあります。
次に、バケットの CORS (オリジン間リソース共有) を設定する必要があります。これにより、アプリケーションは S3 バケット内のコンテンツにアクセスできるようになります。各ルールで、バケットへのアクセスが許可されるアクセス元ドメインのセットを指定し、それらのドメインから許可されるメソッドおよびヘッダーも指定する必要があります。
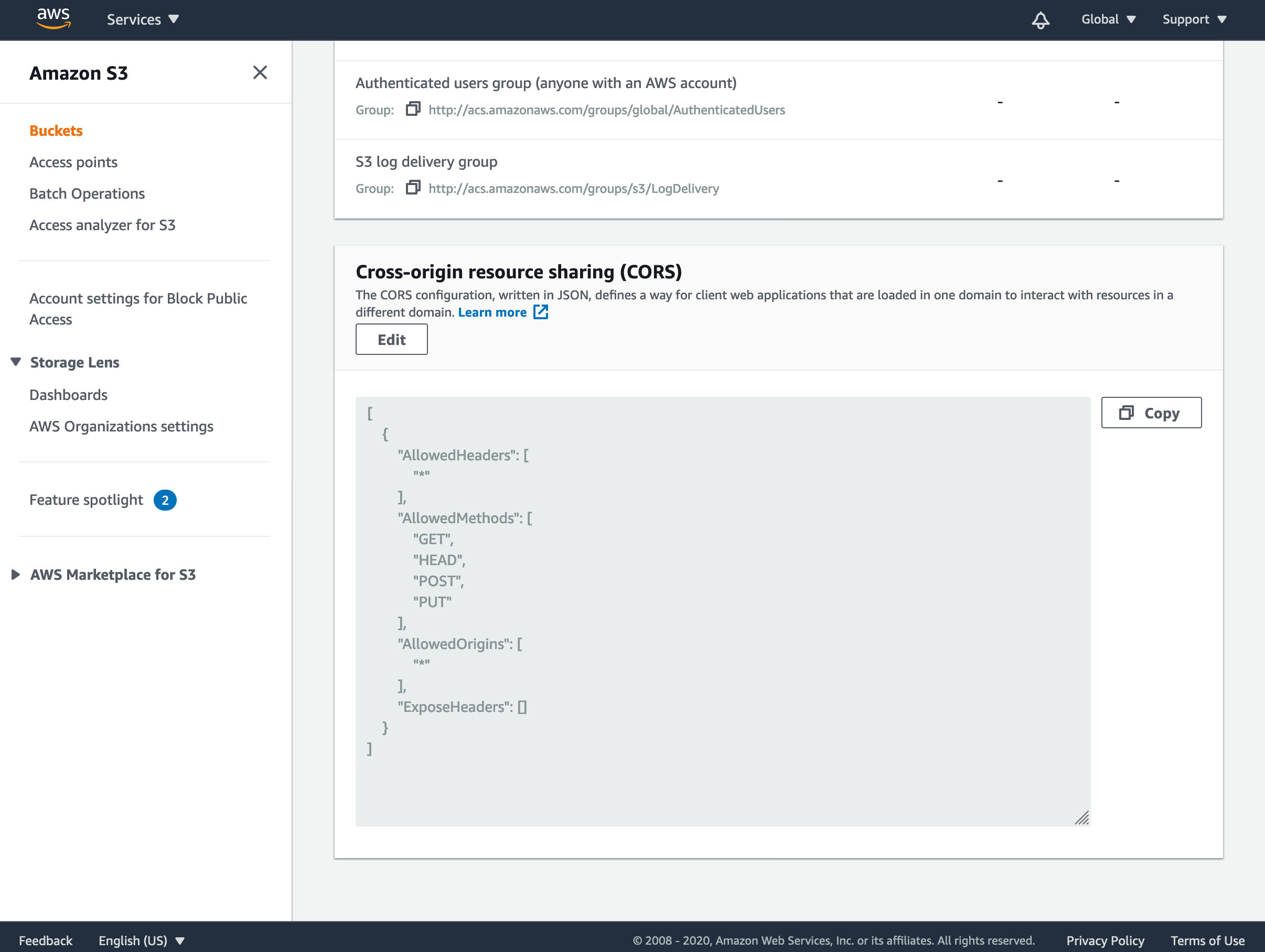
アプリケーションでこれが機能するよう、Edit (編集) をクリックして次の JSON を入力します。
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"HEAD",
"POST",
"PUT"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": []
}
]
Save changes (変更の保存) をクリックしてエディタを閉じます。
これにより、任意のドメインにバケットへのアクセスを許可し、リクエストに含まれるヘッダーを制限しないことを S3 に指示します。セキュリティ保護のために、特定のドメインからのリクエストしか受け取らないように ‘AllowedOrigins’ 配列を変更できます。
このアプリケーション専用の S3 資格情報を使用する場合、AWS アカウントページでさらにキーを生成できます。これにより、このキーのセットが実行できるリクエストのセットを具体的に指定できるため、セキュリティがさらに強化されます。これが望ましい場合は、S3 バケットの 「Edit bucket policy」 (バケットポリシーの編集) オプションで IAM ユーザーも設定する必要があります。AWS の Web ページには、この実行方法を詳細に説明しているさまざまなガイドが掲載されています。
直接アップロード
この記事の目的は、S3 への直接アップロードを実行するために必要なプロセスと手順を、簡単なプロフィール編集シナリオを使用して説明することです。この例では、許可されたユーザーが、アップロードするアバター画像を選択し、アカウントに保存される基本情報をいくつか入力します。
このシナリオでは、次の手順が実行されます。
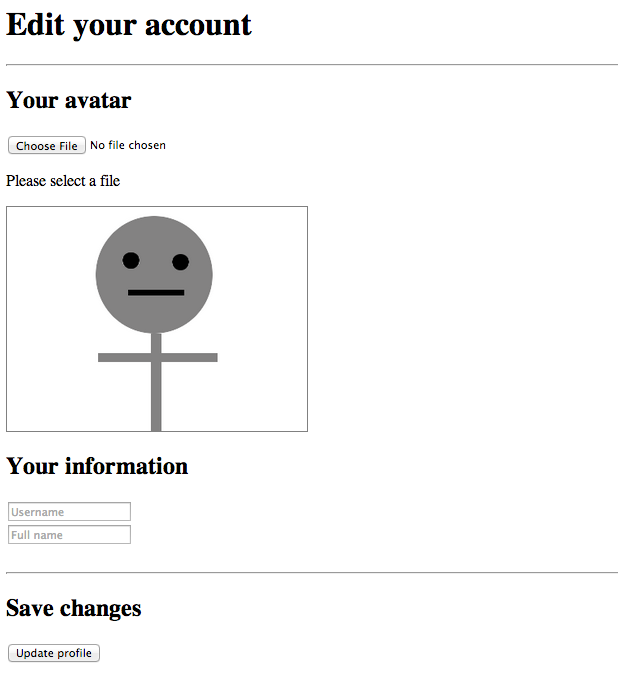
- ユーザーに、自分のアバターとしてアップロードする画像を選択したり、ユーザー名と自分の名前を入力したりするための要素が含まれた Web ページが表示されます。
- ユーザーが選択した画像のプレビューを要素に保持する必要があります。デフォルトでは、アップロードする画像が選択されていない場合、代わりにデフォルトのアバター画像が使用されます (このシナリオでは、画像のアップロードはユーザーにとって事実上、任意です)。
- ユーザーがアップロードされる画像を選択すると、この記事で前に説明したプロセスによって、S3 へのアップロードが自動かつ非同期に処理されます。アップロードが正常に完了すると、選択した画像で画像プレビューが更新されます。
- その後、ユーザーは残りの情報の入力に進むことができます。
- ユーザーが、
Submit ボタンをクリックすると、ユーザー名、アップロードされた画像の名前と URL が Python アプリケーションに送信され、確認と保存が行われます。ユーザーが画像をアップロードしなかった場合、デフォルトのアバター画像の URL が代わりに送信されます。
クライアント側のコードの設定
クライアント側で実装を完了するために必要なサードパーティのコードはありません。
ファイル選択を処理し、Python アプリケーションからリクエストと署名を取得し、最後にアップロードリクエストを実行するための HTML および JavaScript をここで作成できます。
最初に、account.html という名前のファイルをアプリケーションのテンプレートディレクトリに作成し、head やその他の必要な HTML タグのデータをアプリケーションに合わせて適切に設定します。この HTML ファイルの本文には、ファイル入力と、アップロードの最新の進捗状況を反映する要素を含めます。これに加えて、ユーザーが自分のユーザー名とフルネームを入力するためのフォームと、選択されたアバター画像の URL を保持する非表示の input 要素を作成します。
完成した HTML ファイルを確認するには、コンパニオンリポジトリ内の該当するコードを参照してください。
<input type="file" id="file_input"/>
<p id="status">Please select a file</p>
<img id="preview" src="/static/default.png" />
<form method="POST" action="/submit_form/">
<input type="hidden" id="avatar-url" name="avatar-url" value="/static/default.png">
<input type="text" name="username" placeholder="Username">
<input type="text" name="full-name" placeholder="Full name">
<input type="submit" value="Update profile">
</form>
#preview 要素には当初、(新しい画像が選択されない場合にユーザーのアバターになる) デフォルトのアバター画像が保持され、#avatar-url 入力はユーザーが選択したアバター画像の現在の URL を保持します。これらは両方とも、ユーザーが新しいアバターを選択したら、以下で説明する JavaScript によって更新されます。
したがって、ユーザーが最後に Submit (送信) ボタンをクリックすると、アバターの URL とユーザーのユーザー名およびフルネームが指定のエンドポイントに送信され、サーバー側での処理に回されます。
クライアント側のコードでは、次の 2 つの処理を行います。
- 画像を S3 に POST するために使用できるアプリから署名済みリクエストを取得する
- 署名済みリクエストを使用して実際に画像を S3 に POST する
非同期 HTTP リクエストを実行するために、JavaScript の XMLHttpRequest オブジェクトを作成および使用できます。
これを行うには、まず <script> ブロックを作成します。次に、ドキュメントが読み込まれたらファイル入力の変更をリッスンしてアップロードプロセスを開始するコードを記述します。
(function() {
document.getElementById("file_input").onchange = function(){
var files = document.getElementById("file_input").files;
var file = files[0];
if(!file){
return alert("No file selected.");
}
getSignedRequest(file);
};
})();
このコードでは、アップロードされるファイルオブジェクト自体も決定します。ファイルオブジェクトが正しく選択されている場合、ファイルに対する署名済み POST リクエストを取得するための関数の呼び出しに進みます。次に、ファイルオブジェクトを受け入れてそのオブジェクトに対する適切な署名済みリクエストをアプリから取得する関数を記述します。
function getSignedRequest(file){
var xhr = new XMLHttpRequest();
xhr.open("GET", "/sign_s3?file_name="+file.name+"&file_type="+file.type);
xhr.onreadystatechange = function(){
if(xhr.readyState === 4){
if(xhr.status === 200){
var response = JSON.parse(xhr.responseText);
uploadFile(file, response.data, response.url);
}
else{
alert("Could not get signed URL.");
}
}
};
xhr.send();
}
この記事の後半で説明するように、署名済みリクエストの作成にはファイルの名前と MIME タイプが必要であるため、上記の関数はファイルの名前と MIME タイプを GET リクエストにパラメータとして渡します。署名済みリクエストの取得に成功した場合、この関数は、実際のファイルをアップロードするための関数の呼び出しに進みます。
function uploadFile(file, s3Data, url){
var xhr = new XMLHttpRequest();
xhr.open("POST", s3Data.url);
var postData = new FormData();
for(key in s3Data.fields){
postData.append(key, s3Data.fields[key]);
}
postData.append('file', file);
xhr.onreadystatechange = function() {
if(xhr.readyState === 4){
if(xhr.status === 200 || xhr.status === 204){
document.getElementById("preview").src = url;
document.getElementById("avatar-url").value = url;
}
else{
alert("Could not upload file.");
}
}
};
xhr.send(postData);
}
この関数は、アップロードするファイル、S3 リクエストデータ、アバター画像の最終的な場所を表す URL を受け取ります。最後の 2 つの引数は、アプリからの応答の一部として返されます。リクエストが成功した場合、この関数はプレビュー要素を新しいアバター画像に更新し、非表示の入力に URL を格納して、アプリでの保存のために送信できるようにします。
これで、ユーザーがフォームの残り項目を入力完了して Submit (送信) をクリックすると、名前、ユーザー名、アバター画像のすべてを同じエンドポイントに送信できます。
システムの実装後、意図したとおりにページが機能しない場合、console.log() を使用して onreadystatechange 関数で発生したすべてのエラーを記録し、ブラウザのエラーコンソールを使用して問題の診断を試みることを検討してください。
アプリケーションの形式が Web ベースかデバイスベースかを問わず、アプリケーション内でアクティビティが長引いた場合はユーザーに通知し、変更に関する最新の情報を表示することが推奨されます。したがって、ファイルを選択してからアップロードが完了するまでの間に、読み込みインジケータが表示される可能性があります。 このような情報がないと、ユーザーはページがクラッシュしたことを疑い、ページを更新しようとしたり、アップロードプロセスを中断したりする可能性があります。
サーバー側の Python コードの設定
このセクションでは、アップロードリクエストへの署名に使用できる一時的な署名を生成するための Python の使用について説明します。この一時的な署名では、AWS アクセスキーとシークレットアクセスキーを署名の基礎として使用しますが、ユーザーはこの情報に直接アクセスできません。署名の有効期限が切れた後、同じ署名を使用したアップロードリクエストは失敗します。
前述したように、この記事では Flask フレームワーク向けのアプリケーションの本番環境について説明しますが、他の Python フレームワークでの手順も同様です。Python 3 を使用しているユーザーは、Flask の Web サイトで関連情報を確認してから先に進んでしてください。
完成した Python ファイルを確認するには、コンパニオンリポジトリ内の該当するコードを参照してください。
最初に、メインのアプリケーションファイル application.py を作成し、スケルトンアプリケーションを適切に設定します。
from flask import Flask, render_template, request, redirect, url_for
import os, json, boto3
app = Flask(__name__)
if __name__ == '__main__':
port = int(os.environ.get('PORT', 5000))
app.run(host='0.0.0.0', port = port)
現在使用されていないインポートステートメントは後で必要になります。boto3 は、事前署名された POST リクエストを生成する Python ライブラリです。これは、Flask と共に、pip を使用して簡単にインストールできます。
次に、さまざまな URL に対してリクエストが行われたときに正しい情報をユーザーのブラウザに返す役割を担うビューを、同じファイル内に作成する必要があります。最初に、/account へのリクエストに対応し、account.html ページを返すビューを定義します。ユーザーはこのページに含まれるフォームで入力を完了します。
@app.route("/account/")
def account():
return render_template('account.html')
アプリケーションのビューは application.py 内の app = Flask(__name__) と if __name__ == '__main__': の行の間に配置する必要があります。
ここで、同じ Python ファイル内に、クライアント側の JavaScript が画像をアップロードするために使用できる署名を生成して返すためのビューを作成します。これは、S3 へのアップロードを試みる前にクライアントが実行する最初のリクエストです。このビューの応答は /sign_s3/ へのリクエストです。
@app.route('/sign_s3/')
def sign_s3():
S3_BUCKET = os.environ.get('S3_BUCKET')
file_name = request.args.get('file_name')
file_type = request.args.get('file_type')
s3 = boto3.client('s3')
presigned_post = s3.generate_presigned_post(
Bucket = S3_BUCKET,
Key = file_name,
Fields = {"acl": "public-read", "Content-Type": file_type},
Conditions = [
{"acl": "public-read"},
{"Content-Type": file_type}
],
ExpiresIn = 3600
)
return json.dumps({
'data': presigned_post,
'url': 'https://%s.s3.amazonaws.com/%s' % (S3_BUCKET, file_name)
})
バケットが v4 署名を必要とするリージョンにある場合は、boto3 のクライアント設定を次のような宣言に変更できます。
s3 = boto3.client('s3', config = Config(signature_version = 's3v4'))
このコードは、次の手順を実行します。
/sign_s3/ へのリクエストが受信され、S3 バケット名が環境からロードされます。- アップロードされるオブジェクトの名前と MIME タイプがリクエストの
GET パラメータから抽出されます (この段階は他のフレームワークでは異なることがある)。これらのパラメータは、前のセクションで説明された JavaScript によって提供されます。 boto3 ライブラリを使用して S3 クライアントが構成されます。この段階で、前に設定されたAWS_ACCESS_KEY_ID とAWS_SECRET_ACCESS_KEY が環境から自動的に読み取られます。- 次に、事前署名された POST リクエストデータが
generate_presigned_post 関数を使用して生成されます。これに、バケット名、ファイルの名前、アップロードされたファイルをインターネットから読めるようにするためのいくつかのパラメータ、署名済みリクエストの有効期限 (秒単位) が渡されます。 - 最後に、事前署名されたリクエストデータと S3 上の最終的なファイルの場所が JSON としてクライアントに返されます。
すでにファイルに付けられている名前を使用する代わりに、別のカスタマイズされた名前をオブジェクトに割り当てることができます。これは、S3 バケットでの意図しない上書きを防止するために役立ちます。この名前は、たとえば、ユーザーのアカウントの ID に関連付けることができます。そうしない場合、スペースやその他の問題がある文字が含まれる場合に備えて、名前を適切に引用するための何らかの方法を提供する必要があります。さらに、この段階で、特定の種類のファイルへのアクセスを制限するために、アップロードされたファイルのチェックを提供できます。たとえば、.png ファイル以外は処理の続行を許可しないという単純なチェックを実装できます。
最後に、ユーザーがアバターをアップロードし、フォームに入力し、Submit (送信) をクリックした後にアカウント情報を受信するためのビューを application.py 内に作成します。これは POST リクエストになるため、これを ‘許可されるアクセス方式’ としても定義する必要があります。この方式は、URL /submit_form/ へのリクエストに応答します。
@app.route("/submit_form/", methods = ["POST"])
def submit_form():
username = request.form["username"]
full_name = request.form["full-name"]
avatar_url = request.form["avatar-url"]
update_account(username, full_name, avatar_url)
return redirect(url_for('profile'))
この例では、update_account() 関数が呼び出されていますが、この方式の作成はこの記事の対象外です。アプリケーションでは、この段階で、アプリがこれらのアカウントの詳細を何らかの形式のデータベースに保存し、その情報をユーザーのアカウントの詳細の残りと適切に関連付けることができるようにする機能を提供する必要があります。
さらに、プロファイルページの URL は、この記事 (またはコンパニオンコード) では定義されていません。たとえば、アカウントを更新した後に、ユーザーが元の自分のプロファイルにリダイレクトされて、更新された情報を確認できるようになることが理想的です。
アプリの実行
これで、S3 への直接アップロードを実行するための準備がすべて整いました。アップロードをテストするには、すべての変更を保存し、heroku local を使用してアプリケーションを起動します。
これを成功させるには、Procfile が必要になります。Heroku CLI とアプリのローカルでの実行については、「Heroku スターターガイド (Python)」を参照してください。アプリケーションをローカルで実行する前に、自分のマシンの環境変数を正しく設定することも忘れないでください。
$ heroku local
15:44:36 web.1 | started with pid 12417
Ctrl+C を押すとプロンプトに戻ります。アプリケーションで 500 エラー (またはその他のサーバー関連の問題) が発生した場合、デバッグモードでサーバーを起動し、ターミナルエミュレータで出力を確認して問題の解決に役立ててください。たとえば、Flask では次のようになります。
...
app.debug = True
port = int(os.environ.get('PORT', 5000))
app.run(host='0.0.0.0', port=port)
まとめ
この記事では、Python を使用してブラウザから Amazon S3 に直接アップロードし、アップロードリクエストに一時的に署名する方法について説明しました。このガイドおよびコンパニオンコードでは Flask フレームワークを主に扱っていますが、アイデア自体は他の Python アプリケーションにも簡単に応用できます。