最終更新日 2024年04月24日(水)
バックグラウンドジョブを使用して、低速なタスクや CPU 使用率の高いタスクを Web アプリのフロントエンドからオフロードすることで、Web アプリのスケーラビリティを大幅に改善できます。これによって、受信 Web リクエストをフロントエンドで迅速に処理できるようになり、リクエストがバックログに溜まってパフォーマンスの問題が発生する確率が下がります。
一般的な Web アプリでは、500 ミリ秒以内にほとんどのリクエストに応答することが理想的です。アプリの応答に 1 秒以上かかることが常態化している場合、バックグラウンドジョブを追加することでアプリのパフォーマンスが向上するかどうか調査することをお勧めします。
この記事では、アーキテクチャパターンとしてのバックグラウンドジョブの概要を説明し、さまざまなプログラミング言語とフレームワークでその概念を実装する例を示します。
使用事例
バックグラウンドジョブは、以下の種類のタスクで特に役立ちます。
- 外部の API またはサービスとの通信 (Amazon S3 へのファイルのアップロードなど)
- リソース消費の大きいデータ操作の実行 (画像やビデオの処理など)
操作の順序
バックグラウンドジョブを使用するリクエストの処理手順の概要は以下のとおりです。
- バックグラウンドジョブに適しているタスクの実行リクエストが、クライアントからアプリに送信されます。
- (Heroku では Web プロセスと呼ばれる) アプリのフロントエンドがリクエストを受信します。このフロントエンドはタスクをジョブキューに追加し、すぐにクライアントに応答します。応答はリクエストの結果が保留中であることを示します。結果をポーリングするためにクライアントが使用できる URL が応答に含まれる場合もあります。
- タスクがジョブキューに追加されたことを、(Heroku ではワーカープロセスと呼ばれる) 別のアプリプロセスが検知します。このプロセスはタスクをキューから取り出して、タスクの実行を開始します。
- ワーカープロセスは、タスクを完了したら、タスクの結果を保存します。たとえば、Amazon S3 にファイルをアップロードする場合、ファイルの S3 URL を永続化することがあります。
- クライアントは、タスクが完了して結果が得られるまで、定期的にアプリをポーリングします。
例
RSS リーダーアプリの例を考えます。このアプリが提供するフォームでは、読み取る新規 RSS フィールドの URL をユーザーが送信できます。しばらくして、フィードの内容を確認できるページにユーザーが誘導されます。
スケーラブルでないアプローチ
簡単な (ただしスケーラブルでない) 方法でこれを行うには、フォーム送信リクエストの処理と並行して、サードパーティのサイトからフィードの内容を取得します。
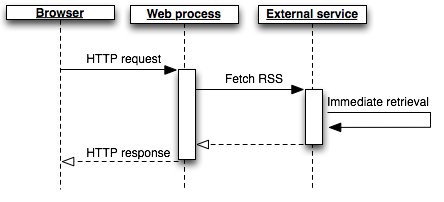
外部ソースからデータをフェッチするためにかかる時間は、予測がきわめて困難です。数百ミリ秒で済む場合もあれば、数秒かかる場合もあります。フィードのサーバーがダウンしている場合、リクエストが 30 秒以上にわたってハングし、最終的にタイムアウトになる可能性もあります。
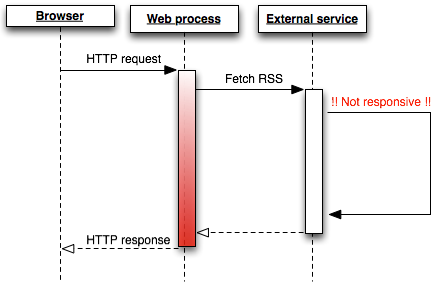
この間アプリのリソースを拘束すると、アプリが他のリクエストを処理できなくなる可能性があり、通常は、ユーザーエクスペリエンスの著しい低下という結果を招きます。この問題は負荷が低い間は顕在化しないこともありますが、アプリの同時ユーザーが複数になるとすぐ、応答時間が不安定になり、H12 やその他のエラーステータスを返すリクエストも出てきます。これらはスケーラビリティの乏しさの指標です。
スケーラブルなアプローチ
より予測可能でスケーラブルなアーキテクチャにおいては、高レイテンシーまたは実行時間の長い作業は、Web レイヤーから隔てられたプロセスでバックグラウンド処理します。また、ユーザーのリクエストには、作業の進捗状況を示す何らかのインジケータを使用してすぐに応答します。
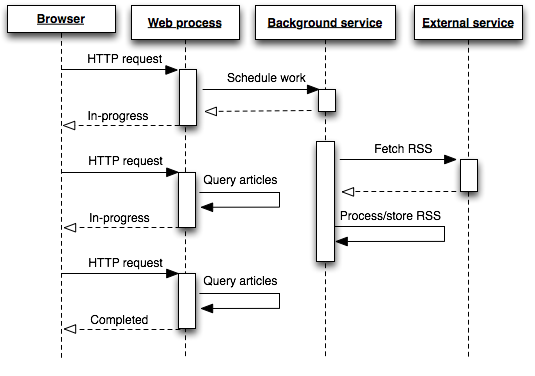
ここでは、Web プロセスとは別に実行され、Web リクエストを処理していない 1 つ以上のバックグラウンドサービスが、そのワークキューから項目を 1 つずつ読み取り、またその作業を非同期的に行います。完了すると、結果は Postgres、Redis、Memcached、または別の永続システムに保存されます。
シーケンス図から判断する限り、クライアント (HTTP) リクエストが以前よりも増加していることから、バックグラウンドのアプローチには何の利点もないように見えます。これは一見もっともらしい考えですが、実際の利点を見落としています。バックグラウンドに送られた作業を取得するためにブラウザで複数のリクエストを実行することが必要かもしれませんが、これらは非常に低レイテンシーで予測可能なリクエストであるという利点があります。実行時間の長いタスクの完了を待機したり、その間にハングしたりするユーザーリクエストを根絶できます。
実行時間の長い作業をバックグラウンドワーカーで処理することには、多くの利点があります。Web dyno の拘束が回避され、Web dyno が他のリクエストにサービスを提供することを防ぎ、サイトの応答性を維持します。サイトの負荷に応じてワーカープロセスを個別に監視、制御、スケーリングできるようになりました。現在の作業の進捗状況を知らせるのみであっても、すべてのリクエストに対してすぐに応答が得られれば、ユーザーエクスペリエンスは大幅に改善されます。
プロセスモデル
Heroku では、アプリケーション固有のプロセスモデルを開発者が指定できます。このモデルには、ワークキューからジョブを取得して処理するバックグラウンドワーカーが含まれることがあります。次に示すのは、Web プロセスタイプと、バックグラウンドジョブを処理するためのプロセスタイプの両方を備える Clojure アプリケーションの Procfile の例です。
必要であれば、ワーカープロセスタイプには worker 以外の名前を付けることができます。webプロセスタイプとは異なり、Heroku では worker には特に重要ではありません。
web: lein run -m myapp.web
worker: lein run -m myapp.worker
Web dyno の数は、Worker dyno の数とは無関係にスケーリングできます。
$ heroku ps:scale web=1 worker=5
実装
バックグラウンド自体は単なる概念です。バックグラウンドジョブをアプリケーションで実装するために利用できる、多くのライブラリとサービスがあります。一般的なツールとしては、データベースを基盤にしたジョブフレームワークやメッセージキューがあります。
さまざまな言語でのバックグラウンドワーカー実装の具体的な例には、以下のものがあります。
| 言語/フレームワーク | チュートリアル |
|---|---|
| Ruby/Rails |
|
| Node.js |
|
| Python |
|
| Go |
|