Table of Contents [expand]
この記事の英語版に更新があります。ご覧の翻訳には含まれていない変更点があるかもしれません。
最終更新日 2024年12月02日(月)
H12 リクエストタイムアウトエラーは、リクエストが 30 秒を超えて応答を待っていることを示します。このエラーの原因として、さまざまな要因が考えられます。H12 エラーの一般的な原因には、次のものがあります。スループット容量 (dyno を追加するために必要) の不足、他のリソースをバックアップする極端に時間がかかっているリクエスト、またはシステム全体の速度を低下させる、通常より高い負荷がかかっているデータベースなどの一部の共有リソース。
ラックタイムアウト
すべての Ruby アプリケーションでラックタイムアウトを使用することをお勧めします。この gem は、ルーターがすでに応答している、30 秒を超えて処理中になっているリクエストに対する作業で Web サーバーが時間を消費しないようにします。アプリケーションでこの gem を使用しないと、リクエストタイムアウトが “スタック状態” になる場合があります。つまり、決して応答されることのないリクエストに対する作業でサーバーが飽和します。
Gemfile で次のように指定します。
gem 'rack-timeout'
次に bundle install を実行し、Git にコミットしてからプッシュします。
ラックタイムアウトは、長いリクエストの発生を防止するわけではなく、長いリクエストが暴走の問題に発展することを防止します。すべてのアプリケーションでラックタイムアウトを使用することを強くお勧めします。
ラックタイムアウトの制限
Ruby プログラミング言語の (タイムアウトのコードが依存する) Thread#raise API の設計のために、ラックタイムアウトが頻繁に起動されすぎるとアプリが不適切な状態になる場合があるという、ラックタイムアウトに関する既知のバグが存在します。
アプリケーションで 1 日に数個を超える H12 エラーが発生している場合は、ラックタイムアウトに関連した競合状態エラーを予測し始めることができます。H12 エラーの数が 1 日あたり 10 ~ 20 を超えると、ラックタイムアウトに関連した例外が発生する可能性が大幅に高くなります。
これらの例外はどのようなものですか? これは通常、不明な動作です。一般には、接続またはスレッドプールに関連していますが、必ずしもそうとは限りません。このエラーが発生すると、通常はプロセスが “不適切な” 状態になり、そのプロセスが強制終了されるか、または dyno 全体が再起動されるまで回復しません。
この問題を緩和するにはどうすればよいですか? Thread#raiseによって競合状態で破損したアプリケーションの状態をリセットするための唯一の方法は、そのプロセスの再起動です。ハイブリッドモードの Puma などのマルチプロセス Web サーバーを使用している場合は、プロセスを安全に終了して Puma の起動代替プロセスを実行できます。これを自動的に行うように rack-timeout を設定するには、次のように設定します。
$ heroku config:set RACK_TIMEOUT_TERM_ON_TIMEOUT=1
詳細は、この機能に関するラックタイムアウトのドキュメントを参照してください。この機能を使用するには、rack-timeout 0.6.0 以上を使用する必要があります。
この設定を行ったとしても、ラックタイムアウトによって H12 リクエストタイムアウトの問題の発生は防止されないことに繰り返し注意する必要があります。アプリケーション内のどこが時間のかかる動作の原因となっているかをデバッグするには、この記事の他のセクションを参照してください。
時間のかかるリクエストの再現
H12 が時間のかかる特定のエンドポイントまたは入力の結果である場合は、この動作を再現できる可能性があります。まず、H12 エラーに関するログを調べます。これを行うと、リクエストに関連付けられたリクエスト ID が見つかります。ログにリクエスト ID のタグを付けるように Rails を設定している場合は、そこから、そのリクエストの完全なログを見つけることができます。
同じパラメータで同じエンドポイントにアクセスすることによって同じ動作を再現するよう試みてください。この動作はまた、どのユーザーが現在ログインしているかなど、他の何らかの状態に関する条件付きである可能性もあります。時間のかかる動作を再現できる場合は、rack-mini-profiler や APM アドオンなどのツールを使用して、時間がかかっているか原因をデバッグしやすくすることができます。
スループットのメトリクス
H12 エラーの原因がアプリケーションの容量不足であり、dyno を追加する場合は、その H12 が現れ始める時刻の前後のログに何らかの兆候が見られることが予測されます。
1 つの兆候は、アプリが受信しているスループットが増加していることです。たとえば、このグラフでは、スループットが徐々に増加して、何となく尖ったピラミッドの形を形成していることがわかります。
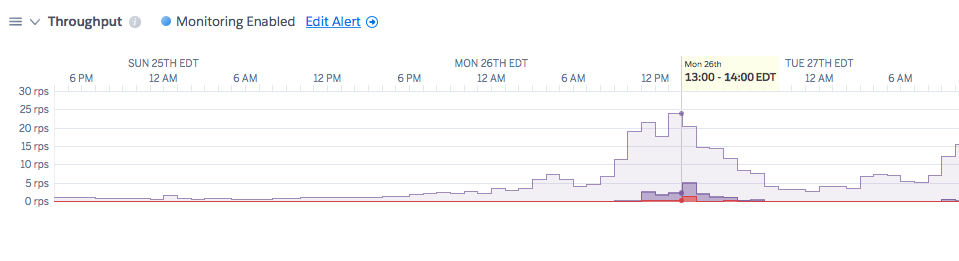
注意: これはメトリクスの例であり、実際のアプリケーションのものではありません。
H12 が増加したスループットの時刻に発生している場合は、dyno が特定の負荷を処理できない可能性があります。修正するには、システムにさらに多くの dyno を追加します。
Puma プール使用
プール使用は、受信トラフィックを処理する Puma Web サーバーの理論的な最大容量を示します。Puma サーバーに、それぞれ 10 スレッドを使用する 2 つのプロセスがある場合、実行中のリクエストを処理する最大並列容量は合計 20 スレッドになります。プール使用のメトリクスを使用すると、アプリケーションがその最大値のどれだけの割合を処理しているかがわかります。 この数値が 20% を下回っている場合は通常、アプリケーションがオーバープロビジョニングされていることを示し、使用している dyno の数を減らすことができます。80% を超えている場合は、システムに余分なバースト容量がなくなっており、dyno を追加するにはシステムをスケールアップする可能性があることを示します。 この例では、ある dyno が H12 イベントの時点で 100% の使用率に達しています。 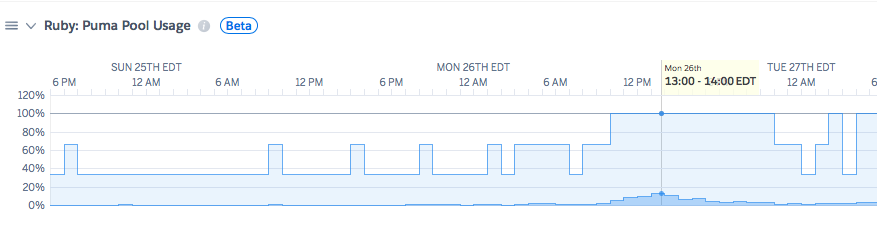 > 注意: これはメトリクスの例であり、実際のアプリケーションのものではありません。 > 注意: この数値を直接使用するには、Puma サーバーのプロセスとスレッドが適度にチューニングされている必要があります。プロセスごとに 1024 個のスレッドを使用して、この割合を人為的に減らすこともできます。その場合でも、スレッド競合でのコンテキストの切り替えに、アプリケーションがそのすべての時間を消費するという問題があります。プロセスとスレッドのチューニングは完全ガイドにとって重要な問題であり、[railsspeed.com/](https://www.railsspeed.com/) は優れたリソースです。また、「[Recommended default Puma process and thread configuration](https://devcenter.heroku.com/articles/deploying-rails-applications-with-the-puma-web-server#recommended-default-puma-process-and-thread-configuration)」(Puma のプロセスとスレッドの推奨されるデフォルト設定) も参照してください。 プール使用は増加したが、スループットが正常に見える場合は、追加のリクエストが受信されなくても、各リクエストに長い時間がかかっている可能性があります。その場合は、外部のデータストア (Postgres など) の “負荷” を調べて、それが H12 イベントの時刻の前後に上昇しているかどうかを確認する必要があります。データサイズ
通常、H12 エラーのデバッグの混乱させる 1 つの側面は、問題の原因がどこにもないように見えることです。コードは先週も先月も正常に実行されたにもかかわらず、突然、問題が発生します。よくある原因の 1 つとして、データサイズの増加と、クエリを制限しないアプリケーションコードがあります。
たとえば、次のコードはデータベース内のユーザー数が 10、100、または 1000 のときは適切に動作しますが、データサイズが増加するにつれ、パフォーマンスは低下し続けます。
@all_users = User.all
scout や skylight などのツールは、本番環境内のこれらの場所を識別するために役立ちます。ローカルには、rack-mini-profiler を有効にして実行することをお勧めします。
上記のコードは、クエリに制限を追加するか、またはページ分割を追加することによって修正できます。膨大なデータセットにわたって繰り返す必要がある場合は、それをリクエスト内ではなく、バックグラウンドワーカーで行い、バッチ処理された繰り返しを許可する find_each などの方法を使用するようにしてください。
データストアの負荷
H12 エラーの原因がどこにもないように見える可能性がある 1 つの状況は、Web dyno 以外のソースからの追加の負荷がかかっている、Postgres または Redis インスタンスなどの共有リソースが存在する場合です。たとえば、1 日に 1 回バックグラウンドでレポートを作成するタスクがある場合は、このタスクの実行中の追加の負荷が Web dyno 上で実行されているクエリのパフォーマンスに全体的な影響を与える可能性があります。
この場合は、SQL のログ記録を有効にしていれば、ログ内のリクエスト ID を使用して H12 リクエストを調べたときに SQL の時間が長くなっていることに気付きます。また、ログ内の Postgres インスタンスの負荷を確認することもできます。次に例を示します。
sample#db_size=4469950648bytes sample#tables=14 sample#active-connections=35
sample#waiting-connections=0 sample#index-cache-hit-rate=0.87073 sample#table-cache-hit-rate=0.47657
sample#load-avg-1m=2.15 sample#load-avg-5m=1.635 sample#load-avg-15m=0.915
sample#read-iops=16.325 sample#write-iops=0 sample#memory-total=15664468kB
sample#memory-free=255628kB sample#memory-cached=14213308kB sample#memory-postgres=549408kB
このデータベースの場合、0.2 以下の負荷は正常ですが、データベースは 2.15 の負荷の状態にあります。データベースで不均衡な時間を費やしているクエリを識別するには、pg-extras プラグインの一部である Heroku pg:outliers コマンドを使用できます。また、data.heroku.com でデータベース情報を表示することもできます。
データベースの負荷の問題をどのように識別して緩和したかについてのケーススタディを詳細に説明しているブログ投稿がここにあります。